Mehrere als PDF-Dateien gescannte Schriftsätze, Entscheidungen und sonstige Dokumente automatisch nach Datum, Verfasser und Inhalt benennen? Das geht, zeigt Christoph Scheuing - und zwar auch mit Open-Source-Werkzeugen.
Sie als Anwältin oder Anwalt kennen das: Scansysteme liefern häufig PDF-Dateien mit Namen wie "20211207235752.pdf". Daran lässt sich zwar der Zeitpunkt des Scans ablesen, ansonsten sind derartige Dateinamen aber wenig aussagekräftig. Für die weitere Verwendung in einem normalen Dateisystem ist es daher hilfreich, den Dateien Namen zu geben, die auf ihren Inhalt hinweisen.
Bewährt hat sich dabei die Voranstellung des Datums des gescannten Dokuments im Format JJJJ-MM-TT (J = Jahr; M = Monat; T = Tag), weil dies bei alphanumerischer Sortierung nach dem Dateinamen eine chronologische Reihenfolge der Dokumente ergibt. Danach sollte im Dateinamen der Verfasser oder die Verfasserin des Dokuments genannt werden. Ein gescannter Schriftsatz der Klägerseite könnte danach etwa wie folgt benannt werden: "2021-12-07 - Klägerin.pdf".
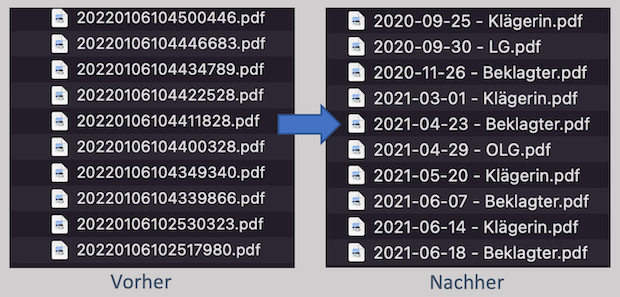
Nun kostet es viel Zeit, jede gescannte PDF-Datei kurz zu öffnen, zu lesen und dann einzeln von Hand nach diesem Muster umzubenennen. Manche kommerzielle Software zur Texterkennung (Optical Character Recognition, OCR) bietet zwar im Rahmen des Scan-Prozesses die Option, eigene Regeln für die Benennung der Dateinamen nach dem Inhalt festzulegen. Das setzt aber meist voraus, dass die gescannten Dokumente optisch alle gleich aufgebaut sind. Bei Dokumenten fremder Herkunft - wie etwa einer Gerichtsakte - ist dies nicht der Fall.
Die gute Nachricht für alle Berufsträgerinnen und -träger: Es ist ohne großen Aufwand möglich, ein automatisiertes System zur flexiblen Benennung von PDF-Dateien selbst aufzusetzen – und zwar so, dass sie nach ihrem Inhalt benannt werden - und das Ganze auch noch mit Open-Source-Tools. Wenn das nichts ist?
Was Sie brauchen
Voraussetzung für die automatisierte Umbenennung von PDF-Dateien ist, dass diese texterkannt sind, also mit einer OCR-Software bearbeitet (oder direkt aus einer Anwendung wie Microsoft Word heraus erstellt) wurden. Ob eine PDF-Datei texterkannt ist, erkennt man daran, ob man Text aus der PDF-Datei markieren und kopieren kann und ob man in der PDF-Datei nach Text suchen kann.
Sofern noch keine Texterkennung stattgefunden hat, gibt es hierzu etwa das Open-Source-Tool "Tesseract", das sich insbesondere mithilfe des ebenfalls kostenlosen Tools "OCRmyPDF" einfach verwenden lässt.
Liegt dann eine texterkannte PDF-Datei vor, ist der Zugriff auf den Textinhalt möglich. Hierzu eignet sich beispielsweise das Open-Source-Tool "pdftotext" aus der PDF-Bibliothek "Poppler". Unter MacOS lassen sich alle erwähnten Tools komfortabel mit dem Paketmananger "Homebrew" installieren.
Kurzanleitung zur Installation der verwendeten Open-Source-Software unter MacOS:

Sobald der bloße Text der PDF-Datei (ohne Formatierung und in der Reihenfolge, wie er auf den gescannten Seiten zu lesen ist) verfügbar ist, kann dieser Text mit sogenannten regulären Ausdrücken (Regular Expressions, Regex) durchsucht werden. Das ist ein mächtiges Werkzeug zum Suchen und Ersetzen von Text mithilfe syntaktischer Regeln (siehe dazu auch hier). Im nächsten Abschnitt zeigen wir Ihnen nützliche reguläre Ausdrücke.
Tipp für Fortgeschrittene: Wenn Sie diese für Ihre Zwecke anpassen, weiterentwickeln und testen möchten, eignen sich Online-Tools wie "regex101".
Datum des Dokuments
Der hier vorgeschlagene Lösungsansatz basiert auf der Annahme, dass das auf der ersten Seite des Dokuments als erstes genannte Datum dasjenige der Abfassung des Dokuments ist. Diese Annahme kann im Einzelfall falsch sein und liefert deshalb nicht sicher das für die Benennung der Datei gewünschte Datum. Dann müssen Sie es gegebenenfalls händisch korrigieren. Im Allgemeinen ist das in einem Schriftsatz oder einer Entscheidung als erstes zu lesende Datum aber dasjenige des Schriftsatzes oder der Entscheidung – für den juristischen Gebrauch dürfte der folgende Vorschlag also sinnvoll sein.
Ein im Format TT.MM.JJJJ gesetztes Datum ließe sich etwa mit dem folgenden regulären Ausdruck finden und in die drei Bestandteile "Tag", "Monat" und "Jahr" zerlegen:
(\d{1,2})\.(\d{1,2})\.(\d{4})
Dreht man die drei so gefunden Gruppen um und ergänzt erforderlichenfalls führende Nullen, erhält man das für die Dateibenennung gewünschte Format JJJJ-MM-TT. Etwas flexibler lässt sich das Datum mit dem folgenden regulären Ausdruck finden und aufspalten:
(?<!\d)(\d|0\d|1\d|2\d|3\d)[\.,]\s{0,3}(\d|0\d|1[012]|Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember)[\.,]?\s{0,3}(19\d{2}|20\d{2}|\d{2}(?!\d))
Verfasser des Dokuments
Zum Auslesen der Verfasserin oder des Verfassers des Dokuments bietet es sich an, dem System eine Liste möglicher Verfasserinnen und Verfasser zu übergeben. Beim Einscannen einer Gerichtsakte sind das etwa die Namen der beteiligten Personen bzw. Kanzleien und Gerichte. Mit einem regulären Ausdruck lässt sich leicht nach dem ersten Treffer aus dieser Liste möglicher Verfasserinnen oder Verfasser auf der ersten Seite einer PDF-Datei suchen. Der reguläre Ausdruck dafür kann wie folgt lauten:
Verfasser1|Verfasser2|Verfasser3
Freilich funktioniert diese Lösung nur, wenn tatsächlich etwa der Kanzleiname schon oben im Briefkopf des Dokuments und noch vor der Bezeichnung des Gerichts im Adressfeld enthalten ist. Dies ist aber regelmäßig der Fall, sodass – wie beim Auslesen des Datums – dieser Ansatz zwar nicht stets zum richtigen Ergebnis führt, sich in der juristischen Praxis aber durchaus bewährt.
Beispielumsetzung unter MacOS mit Keyboard Maestro
Der beschriebene Lösungsansatz lässt sich bei entsprechender Kenntnis ohne größeren Aufwand als Kommandozeilenskript umsetzen. Noch einfacher geht es unter MacOS mit der mächtigen Automatisierungssoftware "Keyboard Maestro", die Sie kostenlos testen und für knapp 40 Euro für die Verwendung auf bis zu fünf Rechnern erwerben können.
Voraussetzung für das hier gezeigte Keyboard-Maestro-Makro ist, dass "pdftotext" und, sofern auch noch nicht texterkannte PDF-Dateien bearbeitet werden sollen, auch "Tesseract" und "OCRmyPDF" installiert sind (siehe zur Installation mit "Homebrew" den obigen Kasten).
Es bietet sich an, dem Keyboard-Maestro-Makro zur Dateiumbenennung die im Finder markierte(n) Datei(en) zu übergeben. Das geht ganz automatisch, wenn Sie ein Finder-Fenster geöffnet und darin eine oder mehrere Dateien markiert haben, bevor Sie das Makro starten. Aufgerufen werden kann das Makro über das Keyboard-Maestro-Menü oder es können auch andere Trigger wie insbesondere eine Tastenkombination dafür definiert werden. In dem unten herunterladbaren Makro ist die Tastenkombination option + command + U vorgesehen.
Wie das Makro funktioniert
Im ersten Schritt zeigt das Makro einen Dialog an, in dem fünf mögliche Verfasserinnen oder Verfassen der zu bearbeitenden PDF-Dateien und deren jeweilige Rolle im Prozess angegeben werden können. Wird für eine mögliche Verfasserin oder einen möglichen Verfasser keine Rolle angeben, so wird für die Dateiumbenennung der angegebene Name als solcher verwendet.
Nach Bestätigung dieses Dialogs mit "OK" durchläuft das Makro der Reihe nach alle ihm übergebenen Dateien. Dabei prüft es zunächst, ob es sich um eine PDF-Datei handelt. Falls ja, versucht das Makro, mit "pdftotext" den Text der ersten Seite der PDF-Datei auszulesen. Scheitert dies mangels Texterkennung der PDF-Datei, führt das Makro mit "OCRmyPDF" selbst eine Texterkennung der ersten Seite der PDF-Datei durch.
Sofern im Dialog mindestens eine Verfasserin oder ein Verfasser angegeben worden ist, sucht das Makro mit einem regulären Ausdruck die oder den auf der ersten PDF-Seite als erste(n) genannte(n) der angegebenen Verfasserinnen oder Verfasser und ersetzt dieses Ergebnis gegebenenfalls durch die für diese Verfasserin oder diesen Verfasser angegebene Rollenbezeichnung.
Sodann sucht das Makro mit einem regulären Ausdruck nach dem ersten Datum auf der ersten PDF-Seite. Findet es ein Datum, so werden Tag und Monat erforderlichenfalls um eine führende Null ergänzt, ein ausgeschriebener Monatsname wird in eine Zahl umgewandelt und eine nur zweistellige Jahreszahl erhält eine "20" vorangestellt.
Sofern für die jeweilige PDF-Datei alle Bezeichnungen gefunden sind, bildet das Makro den neuen Dateinamen nach dem Muster JJJJ-MM-TT – VERFASSER.pdf. Existiert eine Datei dieses Namens schon, fügt es vor der Dateiendung noch einen Unterstrich und einen aufsteigenden Zähler ein. Schließlich benennt es die übergebene PDF-Datei in den neu gebildeten Dateinamen um.
Herunterladen des Makros
Ein nach diesem Bauplan erstelltes Makro können Sie hier herunterladen. Sie dürfen es gerne ohne Einschränkung für Ihre Zwecke verwenden, anpassen und auch weitergeben. Beachten Sie aber bitte, dass weder das korrekte Funktionieren des Makros noch das Fehlen ungewollter Nebeneffekte garantiert werden kann. Es handelt sich bei dem Makro um keine für den Produktiveinsatz gebaute und entsprechend getestete Software. Vielmehr ist nur die Kernfunktionalität enthalten und etwaige Sonderfälle werden nicht sicher abgefangen. Das – quelloffene – Makro stellt lediglich einen Vorschlag und Umsetzungsansatz dar, der ausgebaut und modifiziert werden kann.
Sollten Sie Fragen, Anregungen oder Verbesserungsvorschläge zu dem Makro haben, wenden Sie sich gerne an scheuing@siegmann-partnerschaft.de.
PDF-Dateien automatisch nach Inhalt benennen: . In: Legal Tribune Online, 19.01.2022 , https://www.lto.de/persistent/a_id/47240 (abgerufen am: 27.07.2024 )
Infos zum Zitiervorschlag